Ultra-Fast Language Generation
via Discrete Diffusion Divergence Instruct
Published:
1Purdue University 2University of Texas at Austin 3University of Texas at El Paso 4National University of Singapore
5hi-Lab, Xiaohongshu Inc 6ML Research, Morgan Stanley
We unlock high-quality language generation in the blink of an eye with DiDi-Instruct.
🚀 Feel the Ultra-Fast Generation Speed:
DiDi-Instruct (64x) vs. MDMs (2x) vs. ARMs
Contributions
DiDi-Instruct distills a few-step generator from a masked discrete diffusion language model, achieving up to 64× speed-ups with comparable or superior quality to its teacher and GPT-2 baselines.
Abstract
Fast and high-quality language generation is the holy grail pursued in the age of AI. In this work we introduce Discrete Diffusion Divergence Instruct (DiDi-Instruct), a training-based method that initializes from a pre-trained masked discrete diffusion language model and distills a few-step student for fast generation. The resulting DiDi-Instruct model achieves comparable or superior performance to its dLLM teacher and a GPT-2 baseline while enabling up to 64× acceleration. The theoretical foundation of DiDi-Instruct is a novel framework based on integral KL-divergence minimization, which yields a practical training algorithm. We further introduce grouped reward normalization, intermediate-state matching, and the reward-guided ancestral sampler that significantly improve training stability, model coverage and inference quality. On OpenWebText, DiDi-Instruct achieves perplexities ranging from 62.2 (8 NFEs) to 18.4 (128 NFEs) and reduces additional training wall-clock time by more than 20× compared to competing dLLM distillation methods. We validate the robustness and effectiveness of DiDi-Instruct through extensive ablation studies, model scaling and generation of discrete protein sequences. In conclusion, DiDi-Instruct is an efficient yet effective distillation method, enabling language generation in the blink of an eye.
Background
Fast language sequence generation has been a long-standing goal for large-scale AI systems. Being one of the most typical large language models (LLMs), Auto-regressive models (ARMs) have achieved remarkable success across a wide spectrum of natural language tasks. However, the interior mechanism that underpins their success imposes an inherent bottleneck: tokens are generated sequentially one at a time, limiting parallelism and throughput at scales. Even with advanced computational techniques, such as KV caches, AR models still have a significant throughput ceiling.
Emerging as a competitive language generation paradigm, discrete diffusion large language models (dLLMs) reinterpret text generation as an iterative text tokens denoising process. Starting from a fully corrupted token sequence, dLLMs first train and then apply a learned sequence denoiser several times to recover the clean text token sequences. As a result, this inference paradigm enables dLLMs to use the bidirectional attention inherited from the transformer network, and therefore, can generate sequences with fewer numbers of function evaluations (NFEs) than ARMs.
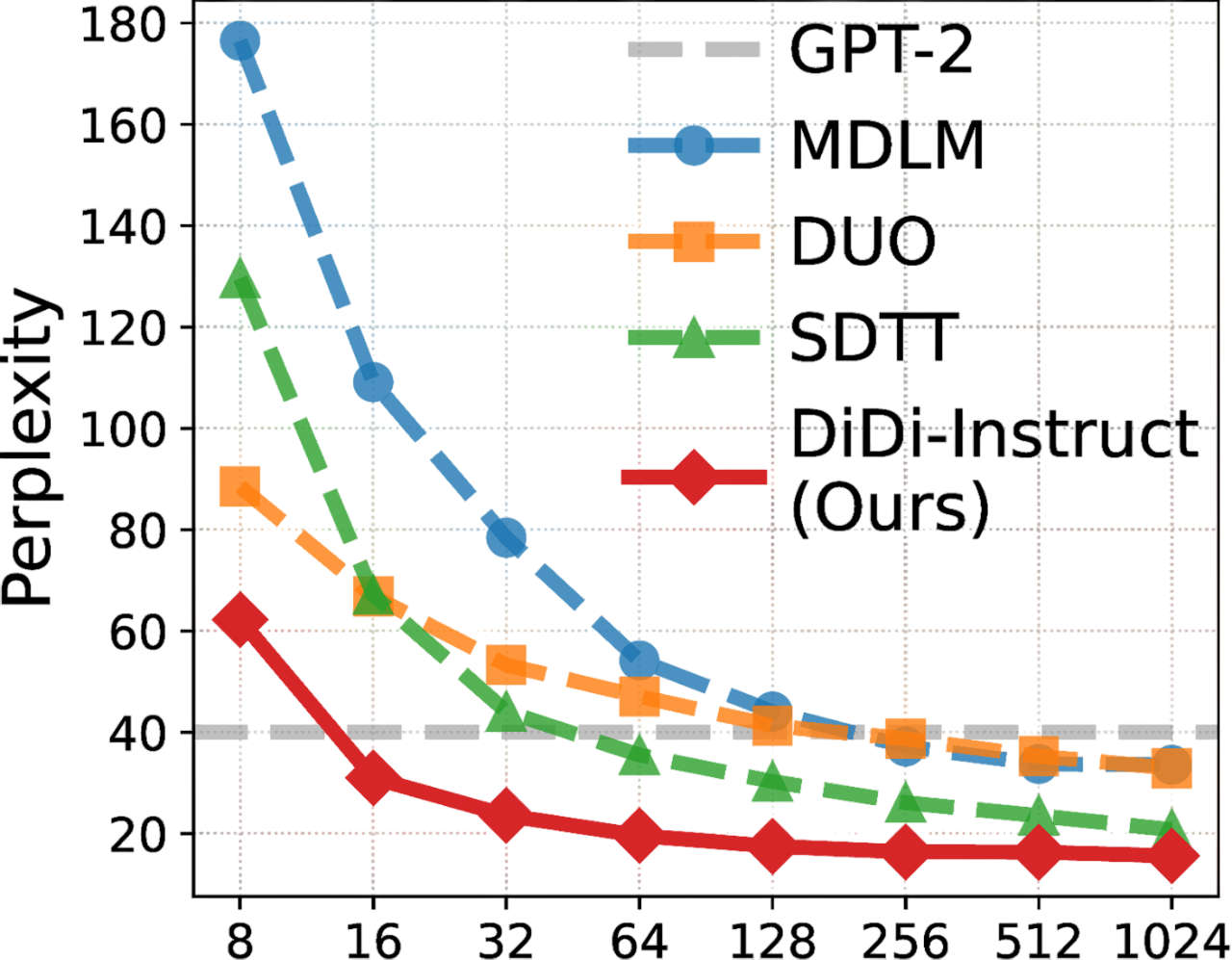
Despite their good performances and improved efficiency, dLLMs still face the inference efficiency bottleneck in generation steps. For instance, on the OpenWebText benchmark, dLLMs still need up to 256 NFEs to match the performance of a GPT2 model. Though these early studies have pioneered the frontier of fast language generation, their generation throughput still has much room to improve: on OpenWebText, even the most recent SDTT can not match the performance of GPT2 baseline within 32 NFEs.
Methodology: DiDi-Instruct
The extension of Integral KL-divergence (IKL) to distill Masked Diffusion Models (MDMs) presents several inherent challenges. This section details the comprehensive solution via advances in objective design, training stability, and inference efficiency.
Integral KL Divergence Framework
The principle of DiDi-Instruct is to minimize an Integral Kullback-Leibler (IKL) divergence between the distributions of a few-step student generation model and a pre-trained dLLM. By minimizing IKL between these distributions across different noise levels \(t \in [0,1]\), the student can match the ability of dLLM in a distribution-matching manner with significantly improved efficiency. The IKL divergence aggregates the discrepancy between student marginal \(\mathbf{q}_{\nu}\) and teacher marginal \(\mathbf{q}_{\theta}\):
\(\mathcal{D}_{\text{IKL}}(\mathbf{q}_{\nu}\|\mathbf{q}_{\theta}) := \int_{0}^{1} \omega(t)\text{KL}(\mathbf{q}_{\nu}\|\mathbf{q}_{\theta})\mathrm{d}t\)
where \(\omega(t)\) is a positive weighting function. IKL integrates this continuum of reliable comparisons, ensuring the student learns the teacher's complete denoising behavior, which leads to more stable and effective training than only matching the final output.
Discrete Diffusion Divergence Instruction
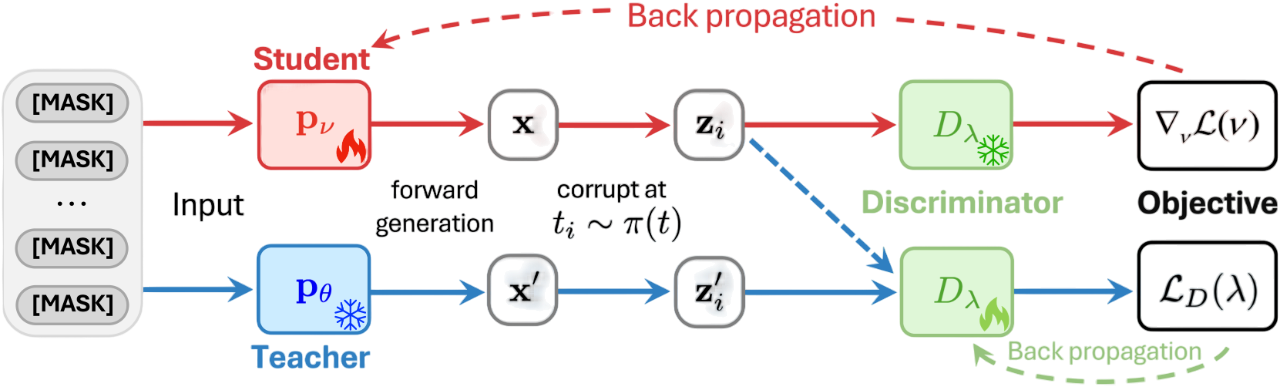
A primary challenge in distilling MDMs is the discrete nature of the state space. The gradient formulation in continuous diffusion models relies on differentiating through \(\mathbf{z}_{t}\), but in MDMs, this forward process involves non-differentiable operations (e.g., arg max). We instead take inspiration from the policy gradient to adapt a mathematically rigorous solution.
We reformulate the distillation objective from a general policy gradient perspective, deriving a simple yet tractable update rule for the few-step student according to some reward function. The gradient of the objective admits a score-function form that does not differentiate through the discrete sampling path:
\(\nabla_{\nu}\mathcal{L}(\nu) = \mathsf{E}_{t\sim\pi(t),\mathbf{x}\sim\mathbf{p}_{\nu},\mathbf{z}_{t}\sim Q}\left[\frac{\omega(t)}{\pi(t)} \cdot R(\mathbf{z}_{t},t) \cdot \nabla_{\nu}\log \mathbf{p}_{\nu}(\mathbf{z}_{t}=\mathbf{m},t=1)\right]\)
where \(R(\mathbf{z}_{t},t) := \log \mathbf{q}_{\nu}(\mathbf{z}_{t},t) - \log \mathbf{q}_{\theta}(\mathbf{z}_{t},t)\) denotes the reward (log-density ratio between student and teacher) at \(\mathbf{z}_{t}\).
Density-Ratio Estimation via Adversarial Discriminator
Since both \(\log\mathbf{q}_{\nu}\) and \(\log\mathbf{q}_{\theta}\) are intractable to compute directly, we avoid modeling the individual densities and instead approximate their ratio. We train an auxiliary discriminator \(D_{\lambda}:\mathcal{V}^{L}\times[0,1]\to(0,1)^{L}\) to distinguish samples generated by \(\mathbf{q}_{\nu}\) and \(\mathbf{q}_{\theta}\). For the optimal discriminator \(D_{\lambda^{*}}(\mathbf{z}_{t},t)\), the density ratio can be expressed as:
\(\frac{\mathbf{q}_{\nu}(\mathbf{z}_{t},t)}{\mathbf{q}_{\theta}(\mathbf{z}_{t},t)} = \frac{D_{\lambda^{*}}(\mathbf{z}_{t},t)}{1-D_{\lambda^{*}}(\mathbf{z}_{t},t)}\)
The reward can then be estimated from the discriminator network \(D_{\lambda}\) by aggregating the log-density ratios over all masked positions in the sequence.
Training Stability Techniques
Grouped Reward Normalization: While the reward estimator is tractable, its direct use in score-function gradients can exhibit high variance. We therefore adopt Group Relative Policy Optimization (GRPO from DeepSeek) to standardize rewards within each mini-batch, significantly reducing gradient variance and improving training stability.
Intermediate-State Matching: While sampling directly from \(\mathbf{z}_{t} = \mathbf{m}\) (\(t = 1\)) to \(\mathbf{x}\) is suitable for one-step generators, it induces collapse in multi-step regimes. To expose the student to intermediate corruption levels, we approximate the score by decomposing it at a randomly sampled time \(t_i \sim \pi(t)\) and its corresponding state \(\mathbf{z}_{i}\). Training with this split score exposes the student to a distribution of intermediate states and mitigates entropy collapse.

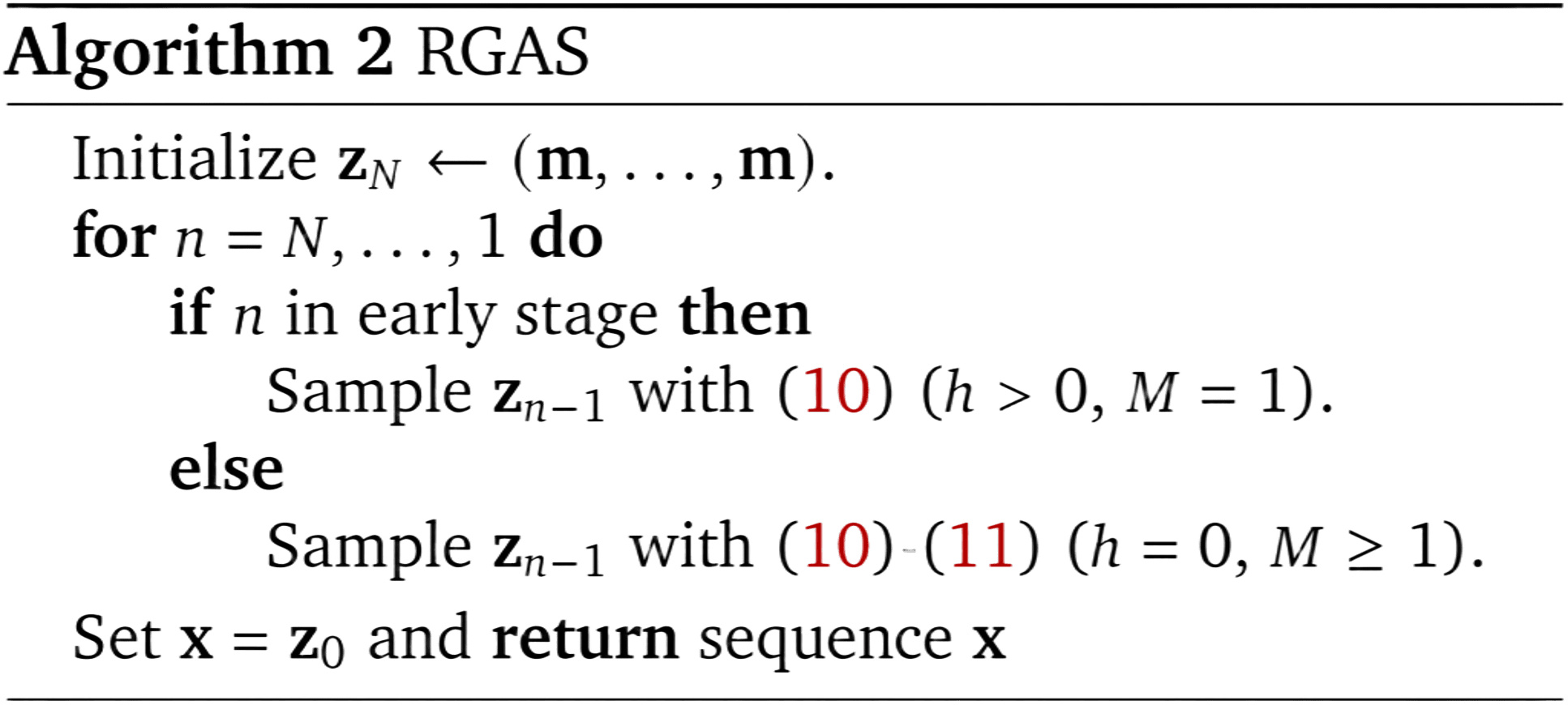
Reward-Guided Ancestral Sampler (RGAS)
We further propose a decoding strategy that leverages the trained discriminator to guide ancestral sampling. Starting from a fully masked sequence \(\mathbf{z}_{N}=(\mathbf{m},\ldots,\mathbf{m})\) at \(t_{N}=1\), the procedure generates samples by iteratively denoising from \(t_{n}\) to \(t_{n-1}\) for \(n=N,\ldots,1\), following the student's backward distribution \(\mathbf{p}_{\nu}(\mathbf{z}_{n-1}|\mathbf{z}_{n})\). RGAS employs a hybrid strategy across the denoising process:
- For early steps (\(t_{n} \approx 1\)): Use gradient tilting (\(h > 0, M = 1\)) to steer global structure toward high-reward regions
- For late steps (\(t_{n} \approx 0\)): Switch to multi-candidate re-ranking (\(h = 0, M > 1\)) where we draw multiple candidates and select based on reward
This approach significantly improves inference quality, reducing generation perplexity by approximately 30%.
Experiments
Our experiments are designed to distill a pre-trained teacher model into an efficient few-step student generator with DiDi-Instruct. All models are trained on OpenWebText. Following standard practices, we tokenize the corpus using the GPT-2 tokenizer, pack sequences to a context length of 1024, and hold out the last 100,000 documents for validation.
Experimental Setup
Our teacher is a 169M parameter MDLM with a Diffusion Transformer (12 layers, 12 attention heads, 768 hidden dimension). We pre-trained this model for 1024 NFEs, achieving a perplexity of 38.53 and an entropy of 5.22. The student model shares an identical architecture to ensure a fair comparison. The discriminator is a 131M parameter network based on the same backbone, but with a new randomly initialized classification head.
The distillation process runs 10,000 iterations using the AdamW optimizer with a learning rate of \(10^{-6}\) and no warm-up. The teacher model was pre-trained on 8 NVIDIA H100 GPUs. In contrast, our DiDi-Instruct distillation is highly efficient, requiring only a single H100 GPU.
State-of-the-Art Performance
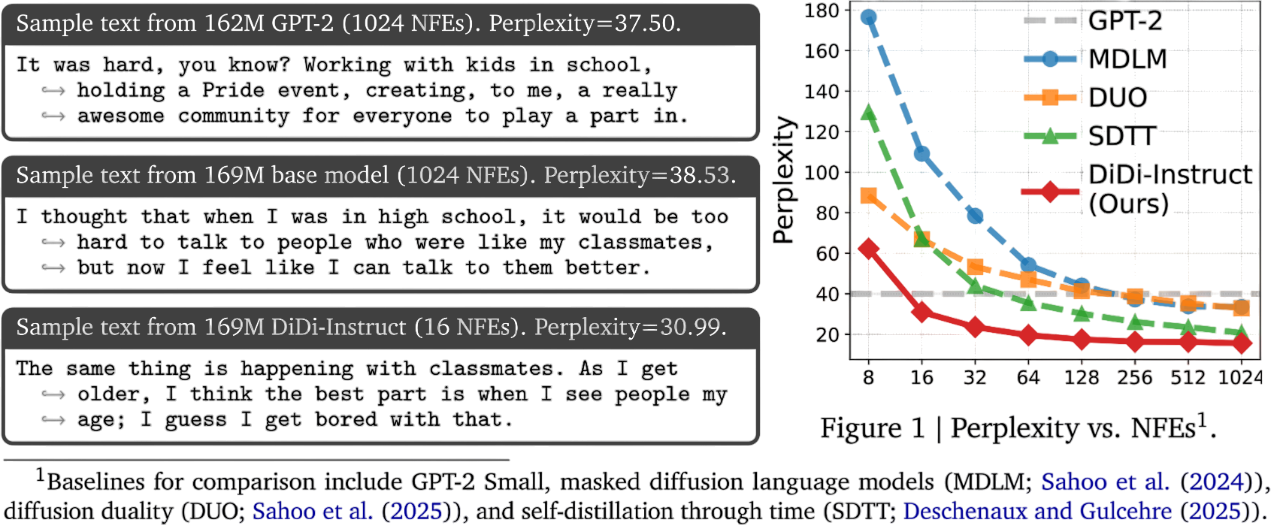
DiDi-Instruct achieves new state-of-the-art performance on the OpenWebText benchmark: consistently lower Perplexity (PPL) across 8 to 128 NFEs, negligible entropy loss, and over 20x faster distillation. With only 16 NFEs, our model's PPL already surpasses that of the 1024-step teacher model. At 1024 NFEs, DiDi-Instruct achieves a final PPL of 15.62, a reduction of over 24% compared to the strongest baseline.
These performance gains are achieved with a negligible loss in diversity; the generative entropy from 8 to 128 NFEs is 5.17, 5.22, 5.20, 5.18, and 5.17, respectively (e.g., 1024-step teacher model is 5.22), indicating sample diversity is well-preserved.
Efficiency and Scalability
DiDi-Instruct offers substantial computational advantages in both training and inference. Our single-round distillation framework completes training in around one H100 GPU hour, in contrast to the 20+ GPU hours required by multi-round methods. During inference, RGAS provides a superior perplexity-latency trade-off, achieving a PPL of 23.54 at a latency of 1.31 s/sequence (32 NFEs), whereas standard ancestral sampling only reaches a PPL of 44.54 (0.71 s/sequence, 32 NFEs).
Protein Sequence Generation
To demonstrate the applicability of our distillation framework beyond natural language generation, we apply DiDi-Instruct to unconditional protein sequence generation. We adopt the Diffusion Protein Language Model (DPLM), pretrained on UniRef50 with 150M parameters, as the teacher model and distill it into a few-step student generator.
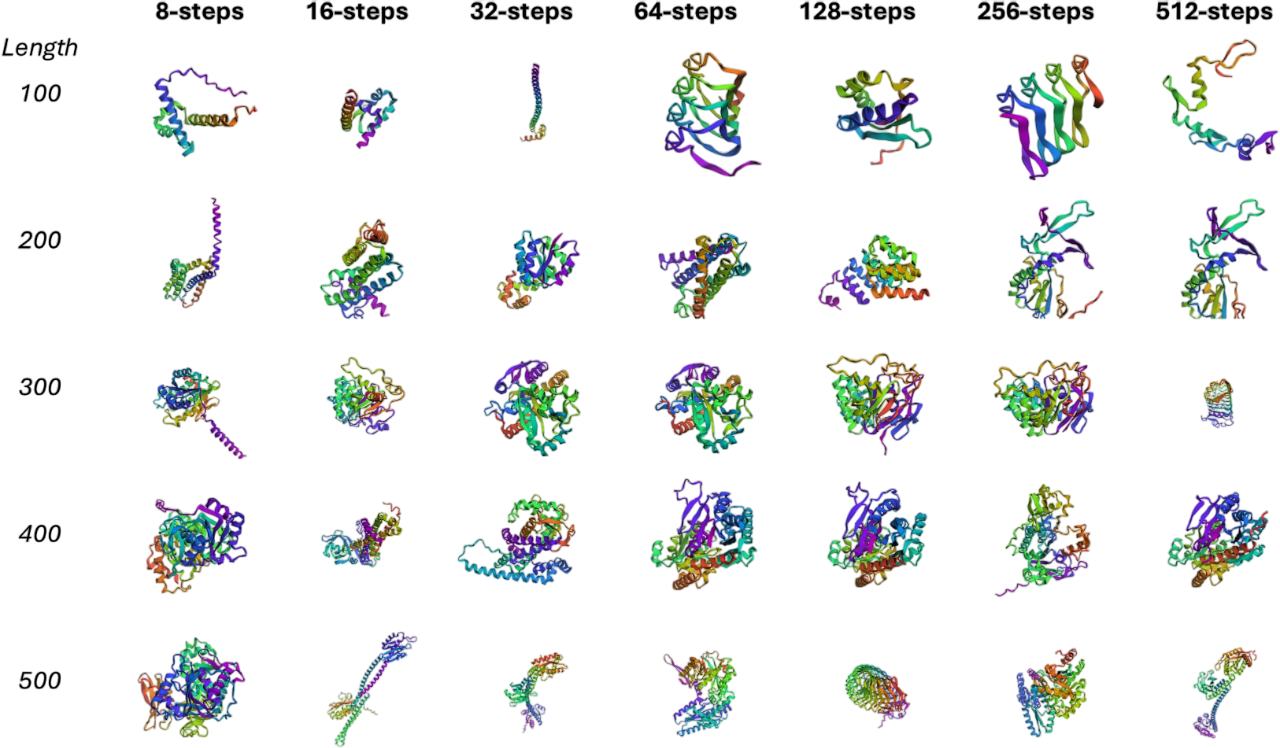
We evaluate sequence quality using the predicted local distance difference test (pLDDT) score, which reflects structural plausibility and foldability. Our results demonstrate that the distilled student consistently achieves superior pLDDT scores across generation settings ranging from 8 to 512 NFEs. Compared to the teacher model, the student not only preserves the ability to generate variable-length protein sequences but also enhances structural quality in most cases. Moreover, our model surpasses the high-confidence threshold (pLDDT > 70) with as few as 8-32 NFEs, while the teacher requires substantially more NFEs to reach a comparable level.
Ablation Studies
We conduct comprehensive ablation studies to validate the contribution of each component in DiDi-Instruct. We perform two types of analyses: a cumulative study that progressively adds techniques to a baseline, showing their synergistic benefits, and a leave-one-out study that removes individual components to confirm their necessity.
| Configurations | 8 NFEs | 16 NFEs | 32 NFEs | 64 NFEs | 128 NFEs | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| PPL↓ | Entropy↑ | PPL↓ | Entropy↑ | PPL↓ | Entropy↑ | PPL↓ | Entropy↑ | PPL↓ | Entropy↑ | |
| Baseline (no tricks) | 803.922 | 5.85 | 311.450 | 5.76 | 174.789 | 5.70 | 113.112 | 5.61 | 96.649 | 5.59 |
| + Score Decompose | 667.830 | 5.83 | 289.720 | 5.76 | 165.809 | 5.70 | 105.880 | 5.61 | 89.350 | 5.59 |
| + Coupled Time t | 101.019 | 5.16 | 75.188 | 5.46 | 48.441 | 5.35 | 35.833 | 5.37 | 30.574 | 5.33 |
| + ω(t) Correction | 94.955 | 5.21 | 75.607 | 5.22 | 31.651 | 5.20 | 25.271 | 5.16 | 20.980 | 5.12 |
| + π(t) Weighting | 92.100 | 5.15 | 43.997 | 5.17 | 32.276 | 5.21 | 26.079 | 5.21 | 21.377 | 5.13 |
| + Regularization | 88.274 | 5.11 | 43.980 | 5.16 | 28.444 | 5.12 | 21.946 | 5.06 | 18.325 | 5.00 |
| + Guided Inference | 62.236 | 5.17 | 38.188 | 5.21 | 24.971 | 5.18 | 21.905 | 5.15 | 18.446 | 5.15 |
| Configurations | 8 NFEs | 16 NFEs | 32 NFEs | 64 NFEs | 128 NFEs | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| PPL↓ | Entropy↑ | PPL↓ | Entropy↑ | PPL↓ | Entropy↑ | PPL↓ | Entropy↑ | PPL↓ | Entropy↑ | |
| w/o Score Decompose | 33584 | 6.77 | 28962 | 6.77 | 23134 | 6.75 | 14634 | 6.64 | 7983 | 6.51 |
| w/o Coupled Time t | 360.75 | 5.42 | 159.43 | 5.43 | 94.859 | 5.45 | 64.639 | 5.35 | 51.121 | 5.39 |
| w/o ω(t) Correction | 82.489 | 5.12 | 41.034 | 5.13 | 30.313 | 5.09 | 25.125 | 5.04 | 18.806 | 5.02 |
| w/o π(t) Weighting | 69.656 | 5.22 | 40.499 | 5.17 | 25.799 | 5.15 | 21.503 | 5.16 | 19.616 | 5.14 |
| w/o Regularization | 84.594 | 5.20 | 30.994 | 5.22 | 23.603 | 5.20 | 19.609 | 5.18 | 17.499 | 5.17 |
| w/o Guided Inference | 88.274 | 5.11 | 43.980 | 5.16 | 28.444 | 5.12 | 21.946 | 5.06 | 18.325 | 5.00 |
| Baseline (with all tricks) | 62.236 | 5.17 | 38.188 | 5.21 | 24.971 | 5.18 | 21.905 | 5.15 | 18.446 | 5.15 |
Key Findings
Our ablation studies reveal distinct roles for each component in our framework:
- Score Decomposition: A non-negotiable cornerstone, providing essential stability without which the model fails to train (PPL > 30,000 when removed)
- Coupled Time t: The most significant performance gains are driven by coupling \(t\) in the objective and score decomposition, reducing 8-step PPL from 600+ to around 100
- Loss Shaping: Weighting functions \(\omega(t)\) and \(\pi(t)\) further smooth optimization, especially around 16 NFEs
- Regularization: Crucial for stability at very few NFEs (≤ 8 NFEs) but detrimental at higher budgets
- Guided Inference: Boosts quality at low NFEs (PPL relative improvement ~30% at 8 NFEs) and enhances diversity at high NFEs (entropy from 5.00 to 5.15)
These findings highlight a hierarchy of importance and nuanced interactions between the techniques, with intermediate-state matching proving to be the foundational element for framework stability.
Conclusion and Future Work
In this work, we introduced DiDi-Instruct, a training-based acceleration framework for fast language generation that distills a high-quality teacher into a few-step student. Our design targets three axes simultaneously: (i) objective design via a tractable policy-gradient update driven by a discriminator-estimated reward; (ii) training stability through score decomposition and grouped reward normalization; and (iii) inference efficiency through reward-guided ancestral sampling with gradient tilting and re-ranking.
Experiments demonstrate strong gains in generation quality, large reductions in training/inference time, and competitive zero-shot generalization, corroborated by comprehensive cumulative, leave-one-out ablations, model scaling up, and protein sequence generation.
We plan to scale DiDi-Instruct to billion-parameter models, which presents a practical challenge due to the GPU memory requirements of concurrently maintaining the teacher, student, and discriminator. Nevertheless, our findings already establish a new state-of-the-art trade-off among comparable methods, with the student model excelling in quality at low NFEs and maintaining diversity at higher computational budgets. We posit that DiDi-Instruct offers a foundational recipe (principled objectives, training stability, and efficient guidance) for developing high-performance generative models in a wide range of fields, including multimodal generation, code generation, and biological sequence design.
BibTeX
If you find this useful, please cite:
@article{zheng2025ultra,
title={{Ultra-Fast Language Generation via Discrete Diffusion Divergence Instruct}},
author={Zheng, Haoyang and Liu, Xinyang and Kong, Cindy Xiangrui and Jiang, Nan and Hu, Zheyuan and Luo, Weijian and Deng, Wei and Lin, Guang},
journal={arXiv preprint arXiv:2509.25035},
year={2025}
}